구성 원칙
| 원칙 | 설명 |
|---|---|
| 대표성 | 실제 사용자 요청 분포를 반영 |
| 난이도 균형 | 쉬움/보통/어려움 비율 관리 |
| 경계 사례 포함 | 모호한 질문, 긴 문서, 노이즈 입력 포함 |
| 버전 관리 | 평가셋 변경 이력과 이유 기록 |
권장 split
golden: 핵심 회귀 테스트용 고정 셋shadow: 신규 이슈 반영용 가변 셋canary: 배포 전 빠른 리스크 확인용 소형 셋
운영 팁
- 신규 장애 케이스를
shadow에 즉시 추가 - 분기마다
golden재검토 - 라벨 가이드를 유지해 평가자 편차 축소
Langfuse Dataset 실행 흐름
1) Dataset 목록에서 실험 대상을 고릅니다
items,runs,last run컬럼으로 유지 상태를 확인합니다.- 배포 전 비교용 데이터셋은 이름을 고정해서 누적 관리합니다.
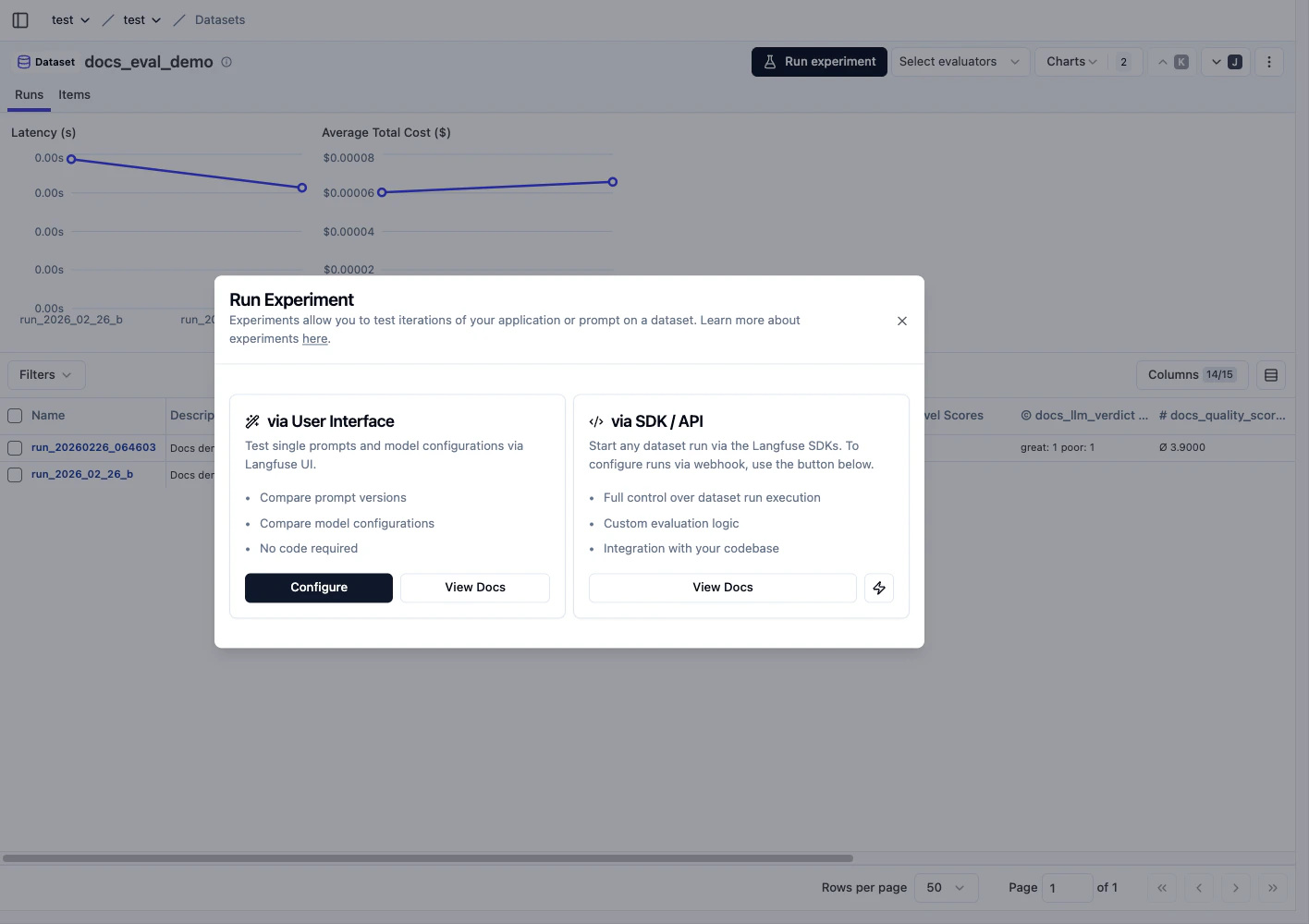
2) Run experiment로 비교 실행을 시작합니다
- UI 기반 실행과 SDK/API 실행 중 하나를 선택합니다.
- 반복 평가라면 SDK/API 경로를 우선 사용합니다.
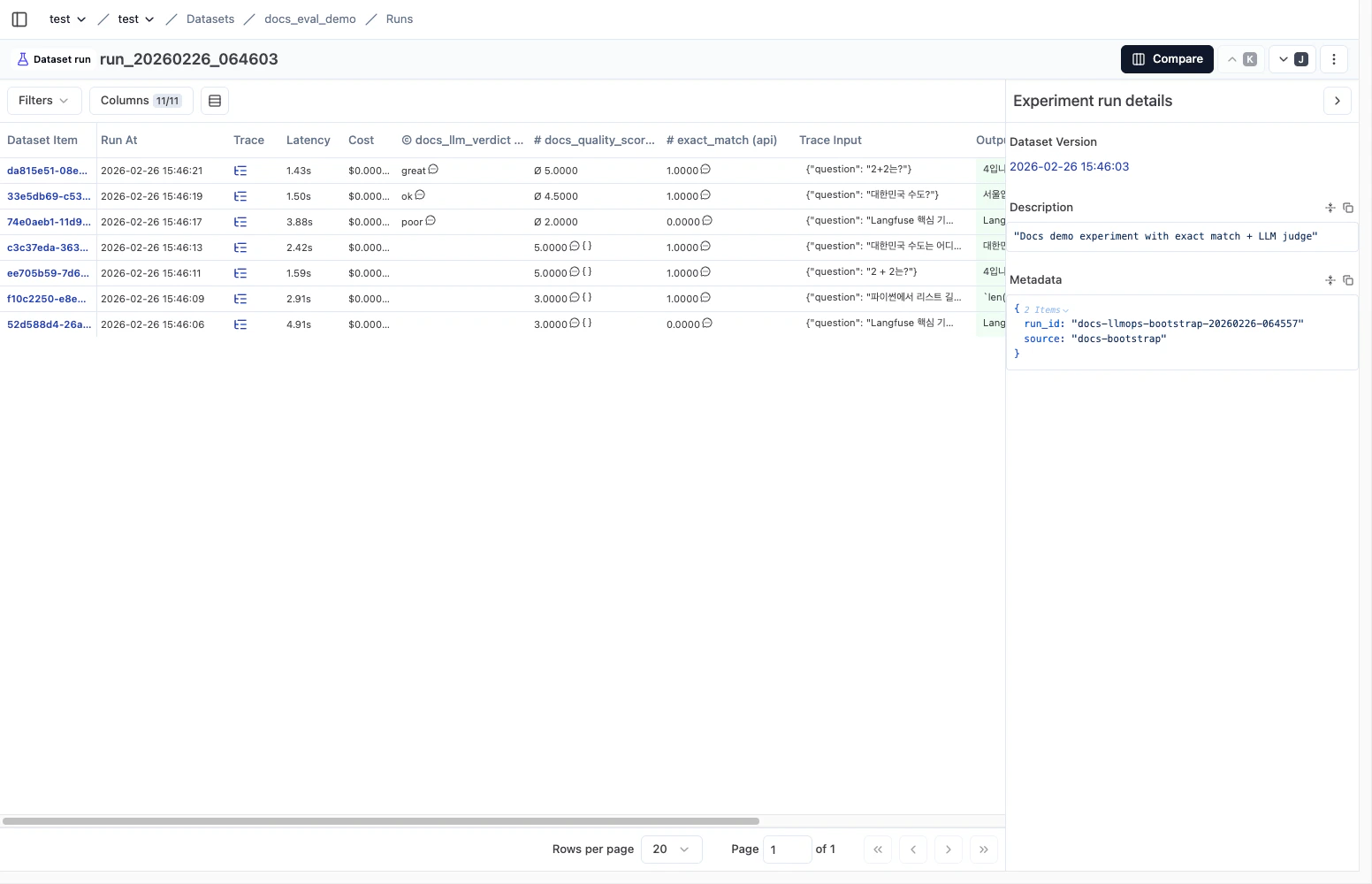
3) Run detail에서 점수와 지연을 함께 확인합니다
- 항목별 latency, cost, score를 한 화면에서 비교합니다.
- 점수가 낮은 샘플의 trace 링크로 바로 이동해 원인을 확인합니다.
실무 적용 체크리스트
- 이 문서의 규칙을 실제 서비스 플로우에 매핑했습니다.
- 측정 지표와 실패 임계값을 숫자로 정의했습니다.
- 변경 전/후를 비교할 기준 데이터셋 또는 로그를 준비했습니다.
- 팀 내 공유 문서(런북/가이드)에 반영했습니다.
자주 나는 실수
- 기준 지표 없이 개선을 선언합니다.
- 한 번에 여러 변수를 바꿔 원인 추적이 불가능해집니다.
- 롤백 조건 없이 배포해 장애 복구가 늦어집니다.
다음 문서
다음: LLM Judge와 Human Review
학습 흐름을 이어서 진행합니다.