span 구조 예시
| span | 포함 정보 |
|---|---|
ingress | 요청 시간, 사용자 컨텍스트, 입력 길이 |
retrieval | 쿼리, top-k, 검색 지연, 문서 ID |
llm_call | 모델명, 토큰 사용량, 응답 시간 |
tool_call | 도구명, 인자, 성공/실패 상태 |
egress | 최종 응답, safety 결과, 총 지연 |
트레이싱 설계 원칙
- 요청 단위 고유 ID를 끝까지 유지
- 개인정보는 저장 전에 마스킹
- 샘플링 정책을 환경별로 분리(dev/stage/prod)
- 재현에 필요한 최소 컨텍스트를 함께 저장
Langfuse 화면 기준 점검 절차
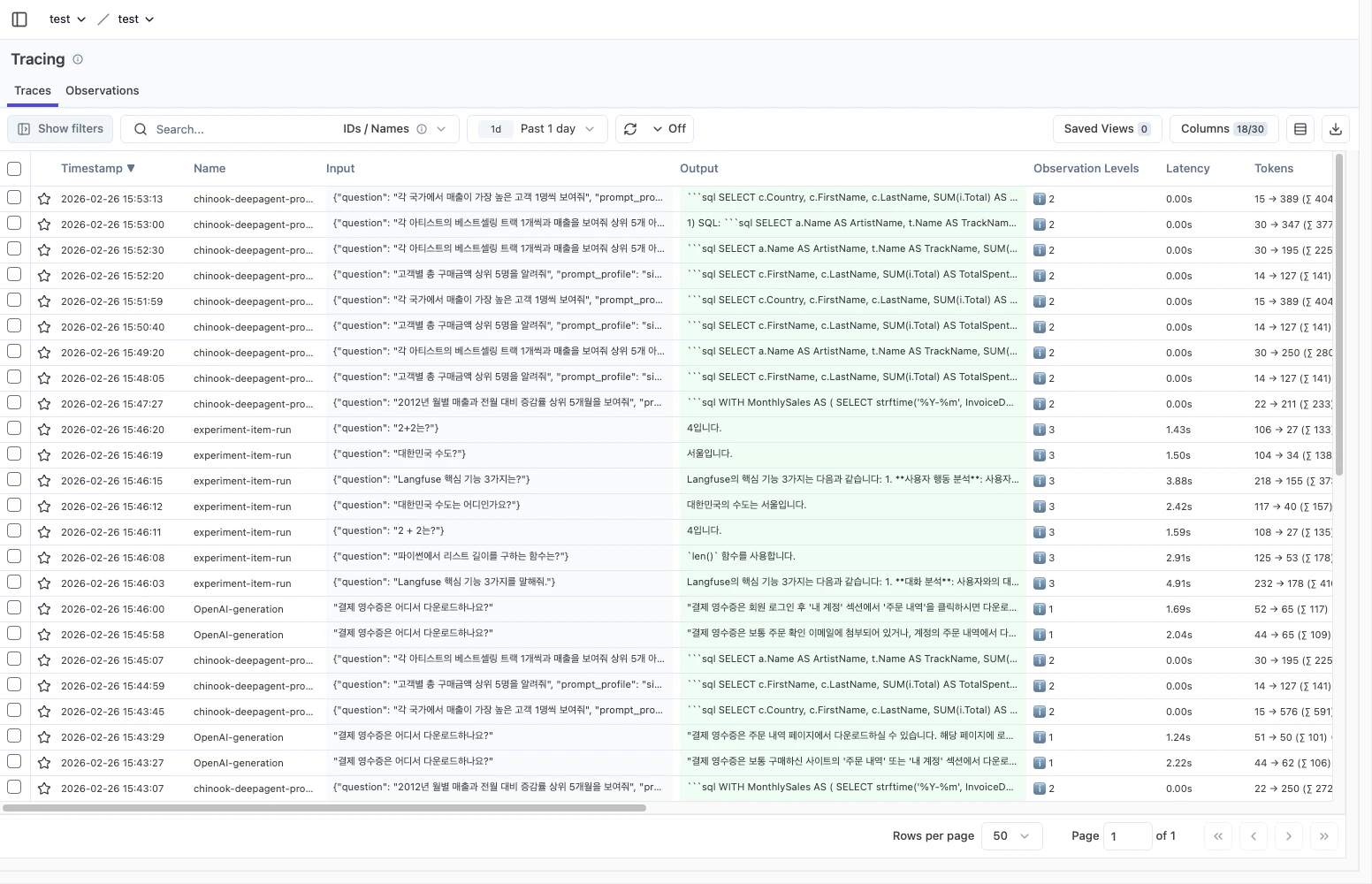
1) Traces 목록에서 실패 패턴을 먼저 좁힙니다
IDs / Names검색에run_id또는 trace name을 넣습니다.- 시간 범위를
1d,7d처럼 고정해서 비교합니다. Observation Levels,Latency,Tokens컬럼으로 이상치를 찾습니다.
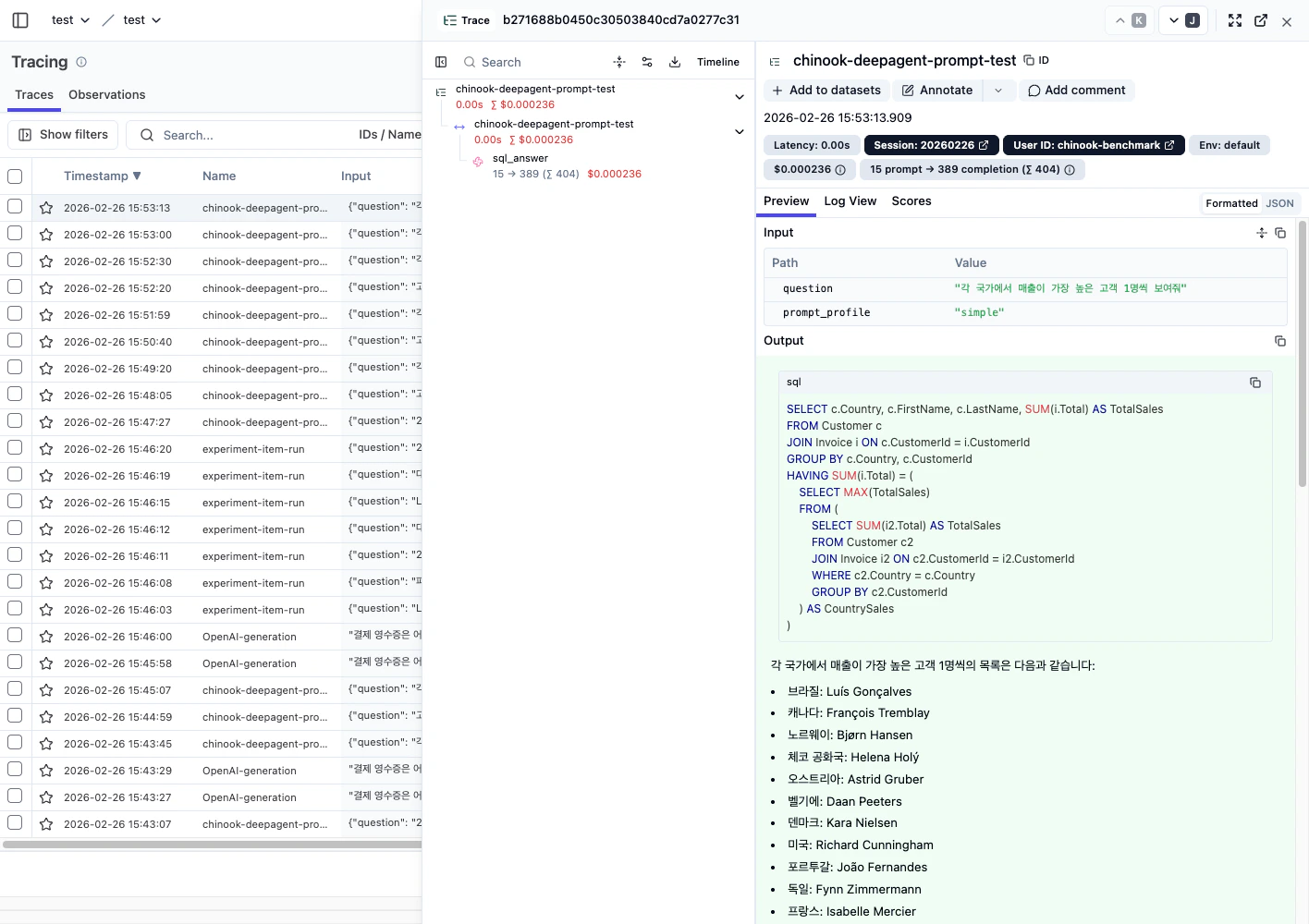
2) Trace Detail에서 원인을 확정합니다
- 우측 상세 패널에서 Preview / Log View / Scores를 순서대로 봅니다.
- 입력, 출력, 메타데이터, 비용을 함께 확인합니다.
- 같은 실패가 반복되면 prompt version, tool call, retrieval 입력을 함께 기록합니다.
장애 분석 질문
- 실패는 특정 모델에서만 발생하는가
- 검색 품질 하락이 생성 실패로 이어졌는가
- 특정 프롬프트 버전에서 에러가 급증했는가
- 툴 호출 타임아웃이 병목인가
실무 적용 체크리스트
- 이 문서의 규칙을 실제 서비스 플로우에 매핑했습니다.
- 측정 지표와 실패 임계값을 숫자로 정의했습니다.
- 변경 전/후를 비교할 기준 데이터셋 또는 로그를 준비했습니다.
- 팀 내 공유 문서(런북/가이드)에 반영했습니다.
자주 나는 실수
- 기준 지표 없이 개선을 선언합니다.
- 한 번에 여러 변수를 바꿔 원인 추적이 불가능해집니다.
- 롤백 조건 없이 배포해 장애 복구가 늦어집니다.
다음 문서
다음: 메트릭과 알림
학습 흐름을 이어서 진행합니다.