역할 분담
| 방식 | 강점 | 한계 | 권장 용도 |
|---|---|---|---|
| LLM judge | 대량 평가 자동화 | 편향/일관성 이슈 가능 | 1차 스크리닝 |
| Human review | 맥락 판단 정확 | 비용/시간 소모 | 최종 검증, 경계 사례 |
결합 패턴
검수 우선순위
- 고객 영향이 큰 업무 흐름
- 정책 위반 가능성이 높은 요청
- 수치/법률/의료 등 고위험 도메인
- 신규 모델/프롬프트 릴리즈 후보
Langfuse 평가 운영 절차
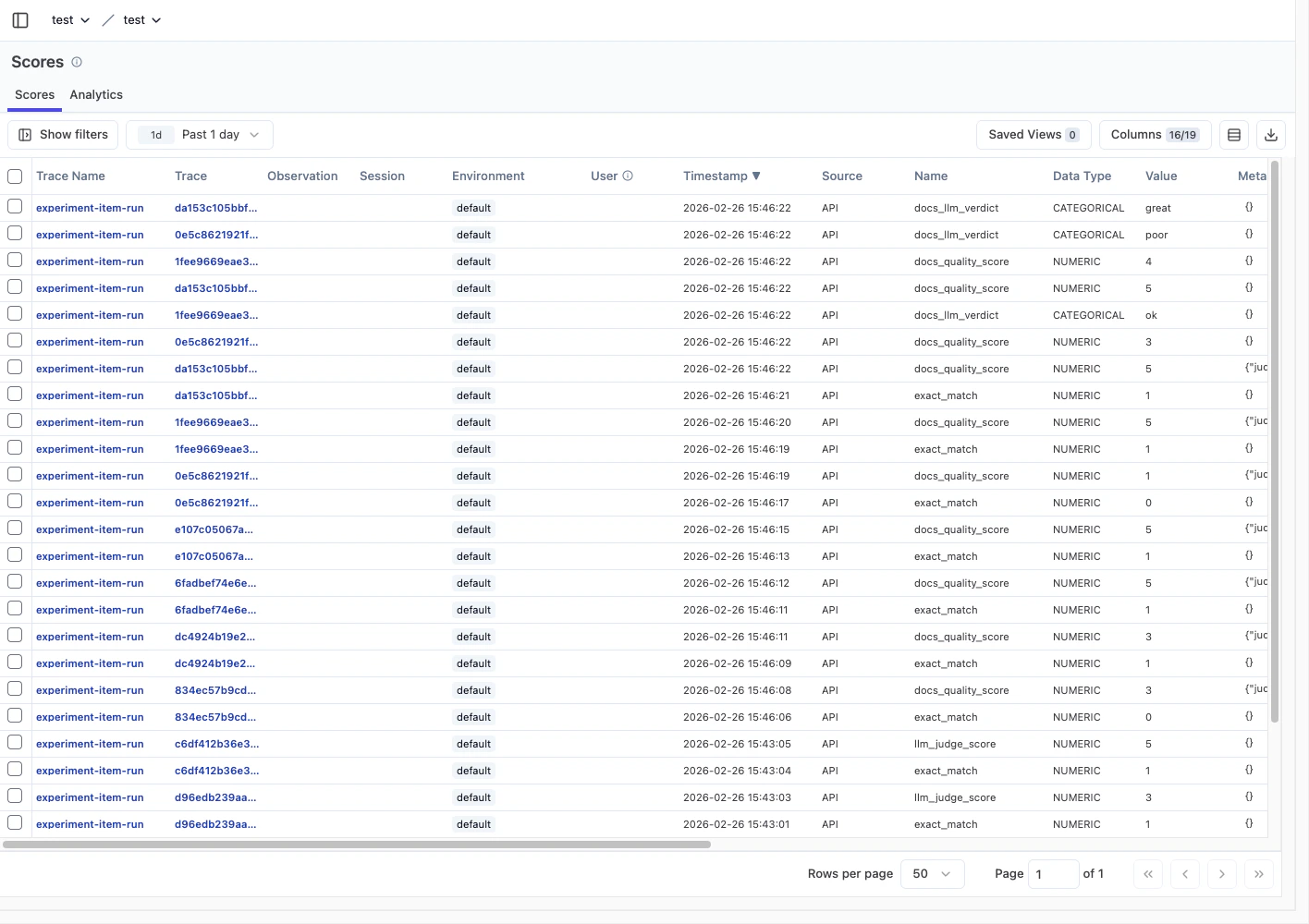
1) Scores 화면에서 점수 적재 상태를 확인합니다
source가 API/UI 어디서 들어왔는지 확인합니다.name,data type,value컬럼으로 지표 품질을 점검합니다.
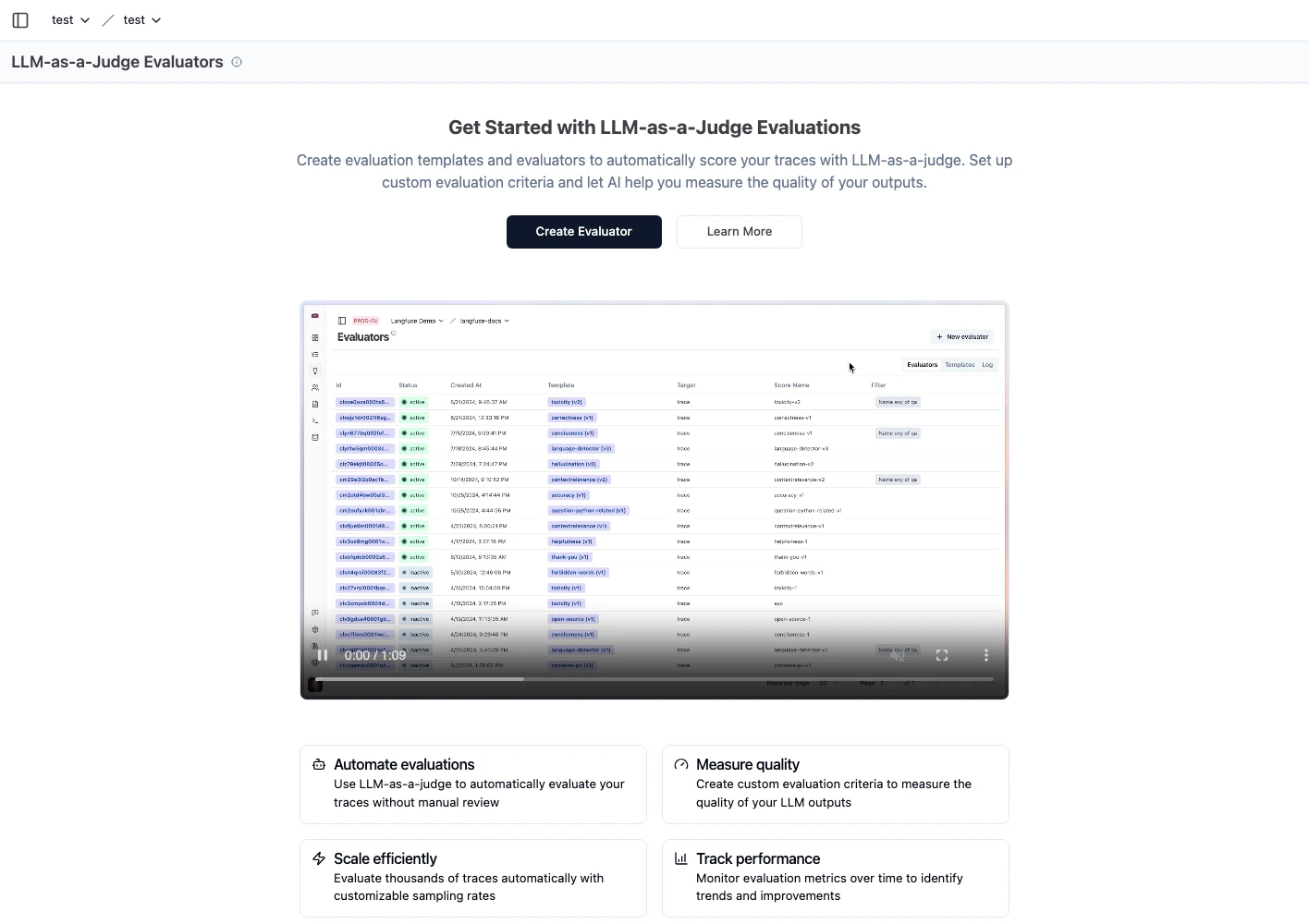
2) LLM-as-a-Judge evaluator를 생성합니다
- 평가 자동화를 위해 evaluator 템플릿을 생성합니다.
- 수동 리뷰 전 자동 1차 필터로 사용합니다.
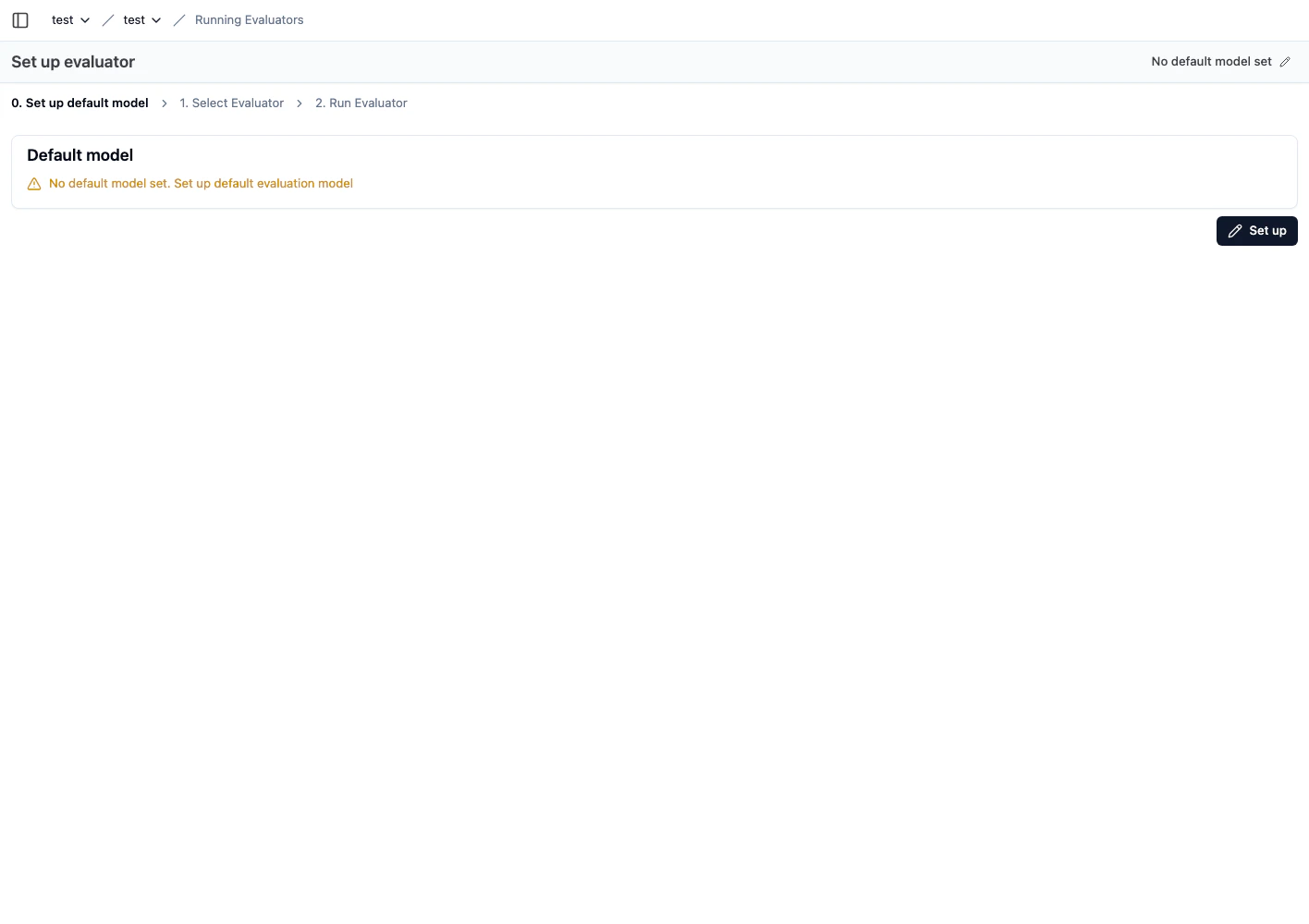
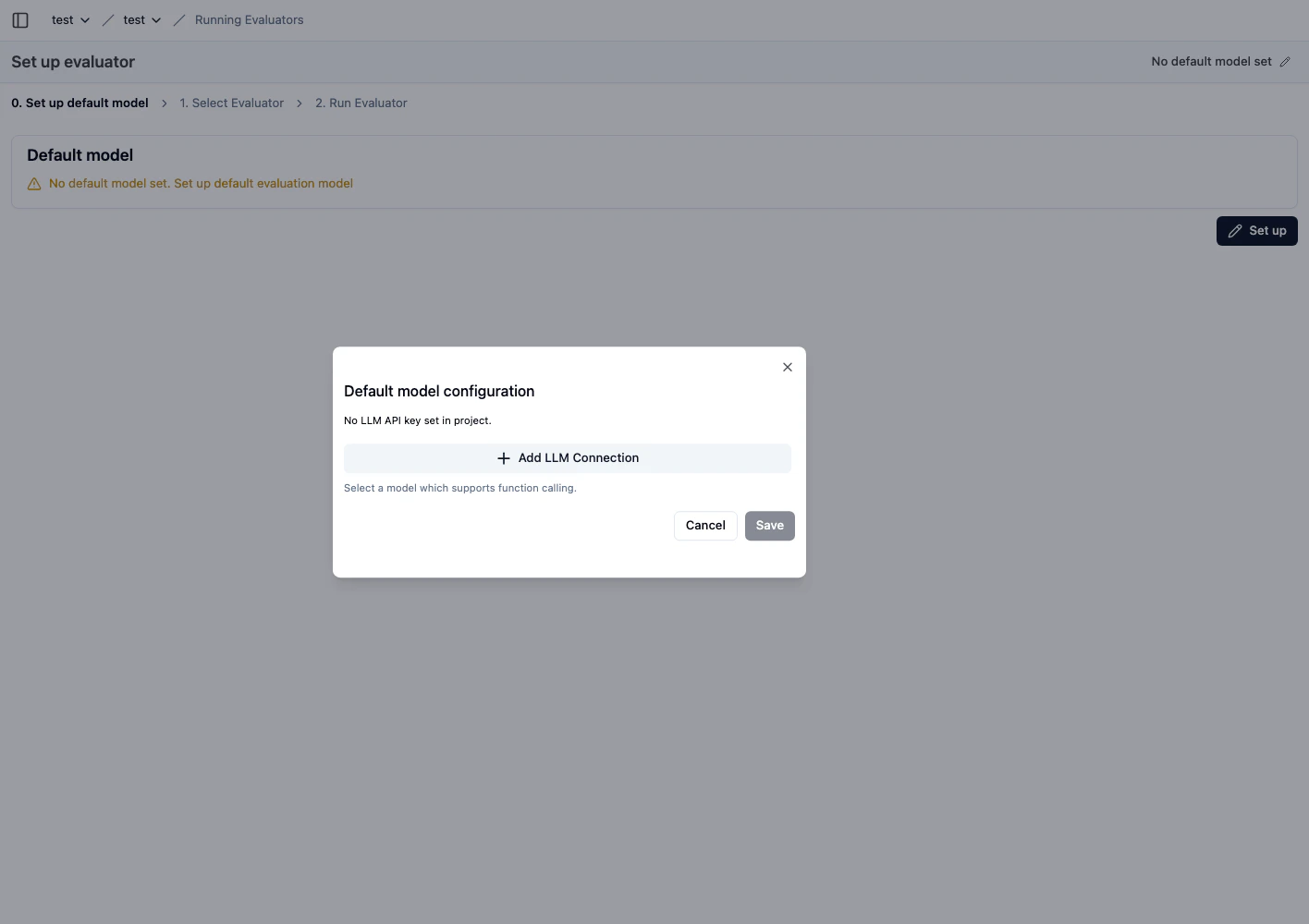
3) 기본 평가 모델을 먼저 연결합니다
- 기본 모델이 없으면 evaluator 실행이 불가합니다.
Set up default model에서 LLM connection을 연결합니다.
실무 적용 체크리스트
- 이 문서의 규칙을 실제 서비스 플로우에 매핑했습니다.
- 측정 지표와 실패 임계값을 숫자로 정의했습니다.
- 변경 전/후를 비교할 기준 데이터셋 또는 로그를 준비했습니다.
- 팀 내 공유 문서(런북/가이드)에 반영했습니다.
자주 나는 실수
- 기준 지표 없이 개선을 선언합니다.
- 한 번에 여러 변수를 바꿔 원인 추적이 불가능해집니다.
- 롤백 조건 없이 배포해 장애 복구가 늦어집니다.
다음 문서
다음: 프롬프트 운영 (PromptOps)
학습 흐름을 이어서 진행합니다.