사전 준비
- Windows 10 이상의 PC
- 인터넷 연결 (설치 파일 다운로드 및 AI 모델 다운로드에 필요)
Ollama 공식 홈페이지에 접속하기
웹 브라우저(크롬, 엣지 등)를 열고 주소창에 ollama.com을 입력하여 접속합니다.화면 중앙에 “Start building with open models”이라는 문구가 보입니다. 오른쪽 상단에 있는 Download 버튼을 클릭합니다.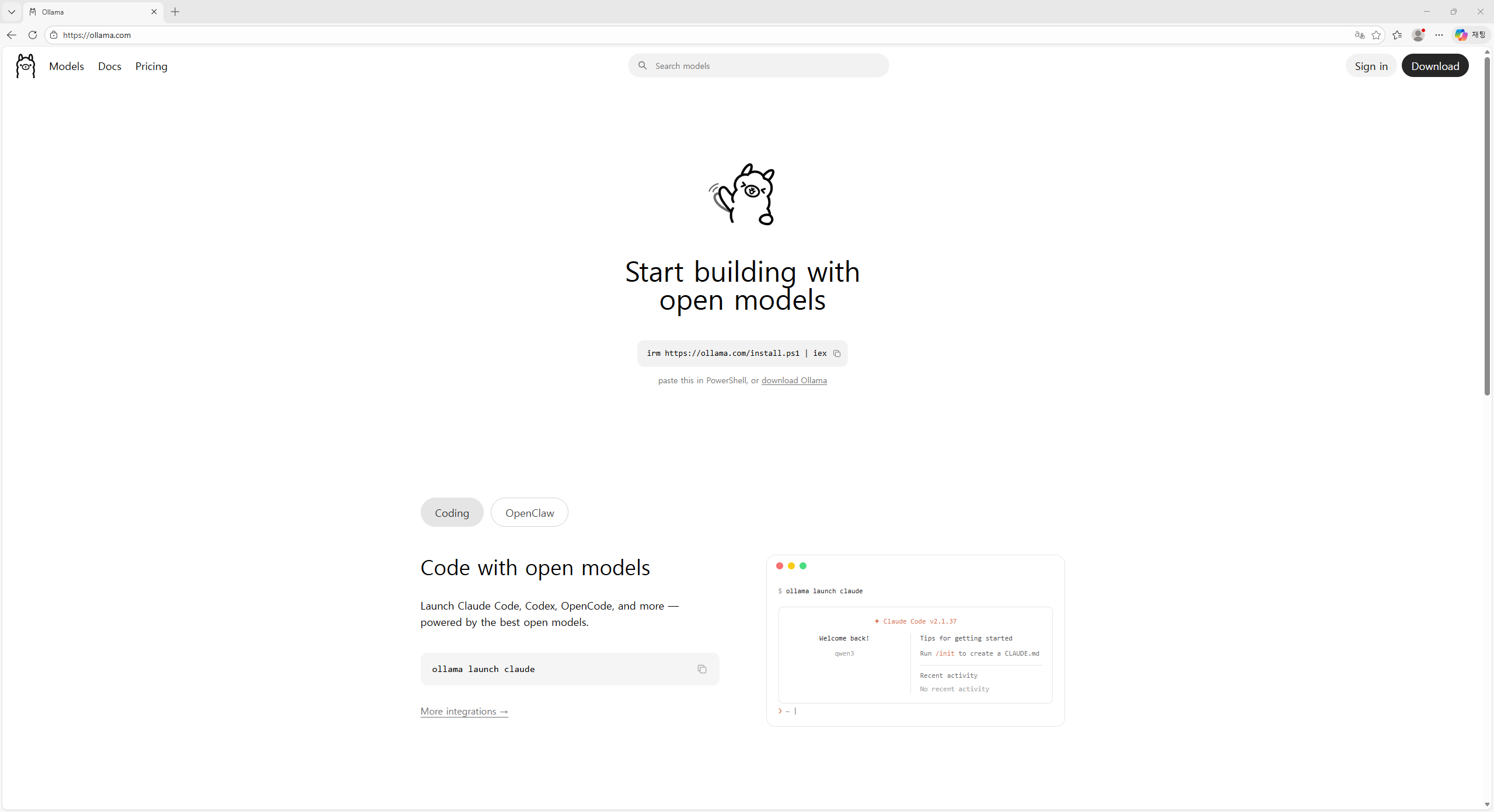
홈페이지에 보이는 PowerShell 명령어(
irm https://ollama.com/install.ps1 | iex)로도 설치할 수 있습니다. 아래에서는 설치 파일 다운로드 방식을 사용합니다.Windows용 설치 파일 다운로드하기
다운로드 페이지가 열리면 상단에 macOS, Linux, Windows 세 가지 운영체제 탭이 보입니다. Windows 탭이 선택되어 있는지 확인합니다(Windows 아이콘이 있는 탭입니다).그 아래에 있는 Download for Windows 버튼을 클릭하면 설치 파일(OllamaSetup.exe)이 다운로드됩니다.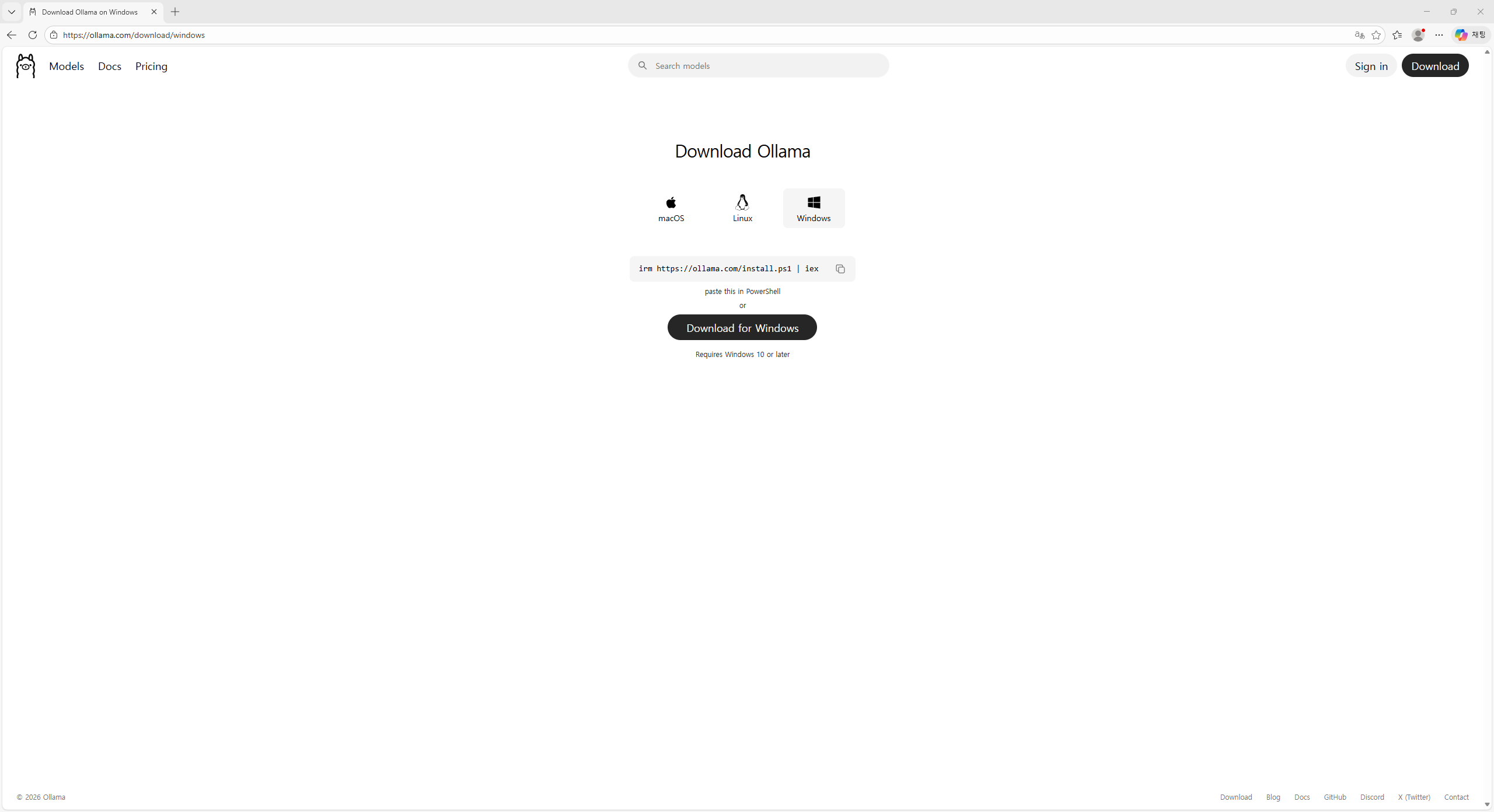
“Requires Windows 10 or later”라고 적혀 있습니다. Windows 10 또는 Windows 11을 사용 중이면 문제없이 설치할 수 있습니다.
설치 프로그램 실행하기
다운로드가 완료되면, 다운로드된 설치 파일(OllamaSetup.exe)을 더블클릭하여 실행합니다.“Setup - Ollama version 0.16.3”이라는 제목의 설치 창이 나타납니다. 화면에 “Let’s get you up and running with your own large language models.”라는 안내 문구가 보입니다.하단의 Install 버튼을 클릭하여 설치를 시작합니다. (오른쪽의 Cancel 버튼은 설치를 취소할 때 사용합니다.)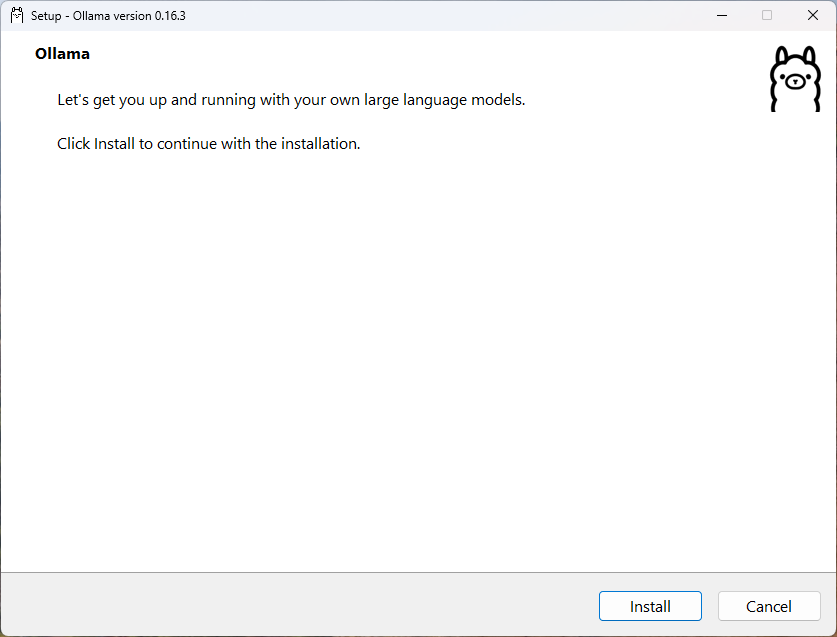
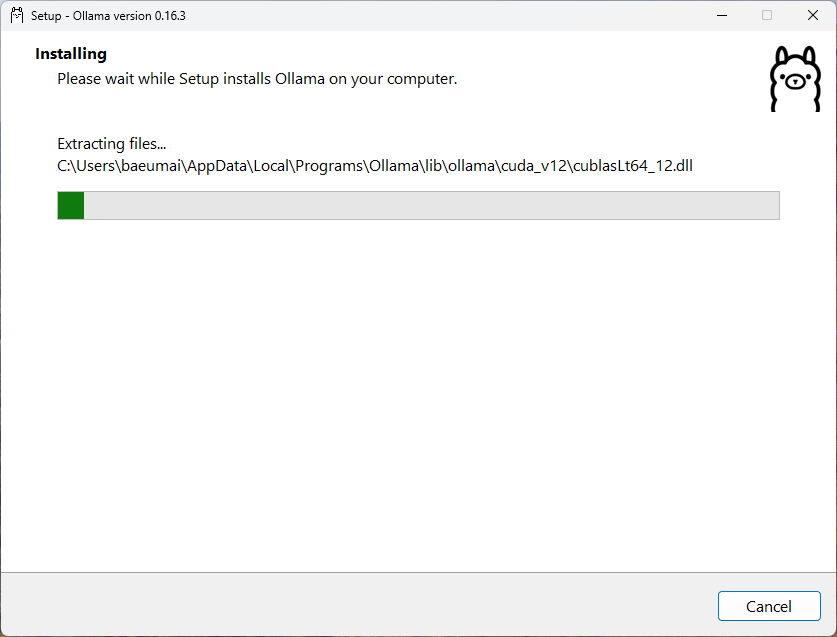
설치 확인하기
설치가 완료되면 Ollama가 시스템 트레이(화면 오른쪽 하단 시계 옆)에 작은 아이콘으로 실행됩니다. 터미널(PowerShell 또는 명령 프롬프트)을 열고 다음 명령어를 입력하면 AI 모델을 바로 다운로드하고 실행할 수 있습니다.다른 모델을 사용하고 싶다면 ollama.com/library에서 사용 가능한 모델 목록을 확인할 수 있습니다. 예를 들어
ollama run gemma2나 ollama run mistral 등을 실행할 수 있습니다.설치 점검 목록
- 관리자 권한/필수 도구 등 사전 요구사항을 먼저 확인했습니다.
- 설치 후 버전 확인 명령어(
--version)를 실행해 정상 설치를 검증했습니다. - PATH/환경변수 변경이 필요한 경우 터미널을 다시 열어 적용 여부를 확인했습니다.
- 문제가 생겼을 때를 대비해 설치 로그 또는 스크린샷을 남겼습니다.
문제 해결 가이드
- 설치 파일이 실행되지 않으면 관리자 권한으로 다시 실행합니다.
- 명령어가 인식되지 않으면 터미널을 새로 열고 PATH 반영 여부를 확인합니다.
- 버전이 맞지 않으면 기존 설치를 정리한 뒤 권장 버전으로 재설치합니다.
- 설정 변경 후 동작이 이상하면 시스템 재시작 후 다시 확인합니다.
관련 문서
Setup 홈
운영체제별 설치 흐름을 다시 확인합니다.
다음: Claude Desktop
다음 설치 단계를 이어서 진행합니다.